Stable Diffusion 3.5 Large Turbo
stableDiffusion35_largeTurbo.safetensors Checkpoint / SD 3.5 Large Turbo
- Model Name
- Stable Diffusion 3.5 Large Turbo
- Version
- Large Turbo
- Creator
- theally
- Size
- 15.33 GB
- Downloads
- 8,439
- BTIH
- 7EF0E8C120EFC984963DFEB7A058B1FF524E0303
- BTMH
- EA716E7F9D94ACBCC072900FDBDC580EC691893EF12370BED3719141DBA8EAD3
- SHA256
- FB64610BF8D73EB064B8D528EEF85D062BF2B4B1204FF7BC73E57AD28B24489C
- Upload Date
- 6 months ago
- Uploader
- CivitasBay.org
- Status
- 2 Seeders0 Peers
Please see our Quickstart Guide to Stable Diffusion 3.5 for all the latest info!
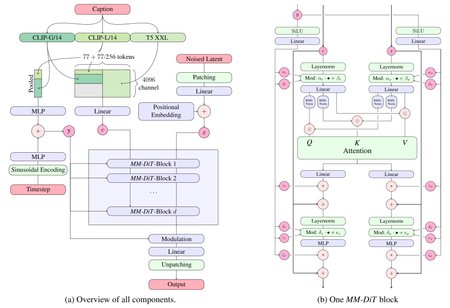
Stable Diffusion 3.5 Large Turbo is a Multimodal Diffusion Transformer (MMDiT) text-to-image model with Adversarial Diffusion Distillation (ADD) that features improved performance in image quality, typography, complex prompt understanding, and resource-efficiency, with a focus on fewer inference steps.
Please note: This model is released under the Stability Community License. Visit Stability AI to learn or contact us for commercial licensing details.
Model Description
Developed by: Stability AI
Model type: MMDiT text-to-image generative model
Model Description: This model generates images based on text prompts. It is an ADD-distilled Multimodal Diffusion Transformer that use three fixed, pretrained text encoders, and with QK-normalization.
License
Community License: Free for research, non-commercial, and commercial use for organizations or individuals with less than $1M in total annual revenue. More details can be found in the Community License Agreement. Read more at https://stability.ai/license.
For individuals and organizations with annual revenue above $1M: Please contact us to get an Enterprise License.
Model Sources
For local or self-hosted use, we recommend ComfyUI for node-based UI inference, or diffusers or GitHub for programmatic use.
ComfyUI: Github, Example Workflow
Huggingface Space: Space
Diffusers: See below.
GitHub: GitHub.
API Endpoints:
Implementation Details
QK Normalization: Implements the QK normalization technique to improve training Stability.
Adversarial Diffusion Distillation (ADD) (see the technical report), which allows sampling with 4 steps at high image quality.
Text Encoders:
CLIPs: OpenCLIP-ViT/G, CLIP-ViT/L, context length 77 tokens
T5: T5-xxl, context length 77/256 tokens at different stages of training
Training Data and Strategy:
This model was trained on a wide variety of data, including synthetic data and filtered publicly available data.
For more technical details of the original MMDiT architecture, please refer to the Research paper.

- udp://tracker.opentrackr.org:1337/announce
- udp://open.demonii.com:1337/announce
- udp://open.stealth.si:80/announce
- udp://tracker.torrent.eu.org:451/announce
- udp://tracker.qu.ax:6969/announce
- udp://tracker.bittor.pw:1337/announce